
The remarkable multimodal capabilities demonstrated by OpenAI's GPT-4 have sparked significant interest in the development of multimodal Large Language Models (LLMs). A primary research objective of such models is to align visual and textual modalities effectively while comprehending human instructions. Current methodologies often rely on annotations derived from benchmark datasets to construct image-dialogue datasets for training purposes, akin to instruction tuning in LLMs. However, these datasets often exhibit domain bias, potentially constraining the generative capabilities of the models. In an effort to mitigate these limitations, we propose a novel data collection methodology that synchronously synthesizes images and dialogues for visual instruction tuning. This approach harnesses the power of generative models, marrying the abilities of ChatGPT and text-to-image generative models to yield a diverse and controllable dataset with varied image content. This not only provides greater flexibility compared to existing methodologies but also significantly enhances several model capabilities. Our research includes comprehensive experiments conducted on various datasets using the open-source LLAVA model as a testbed for our proposed pipeline. Our results underscore marked enhancements across more than ten commonly assessed capabilities.
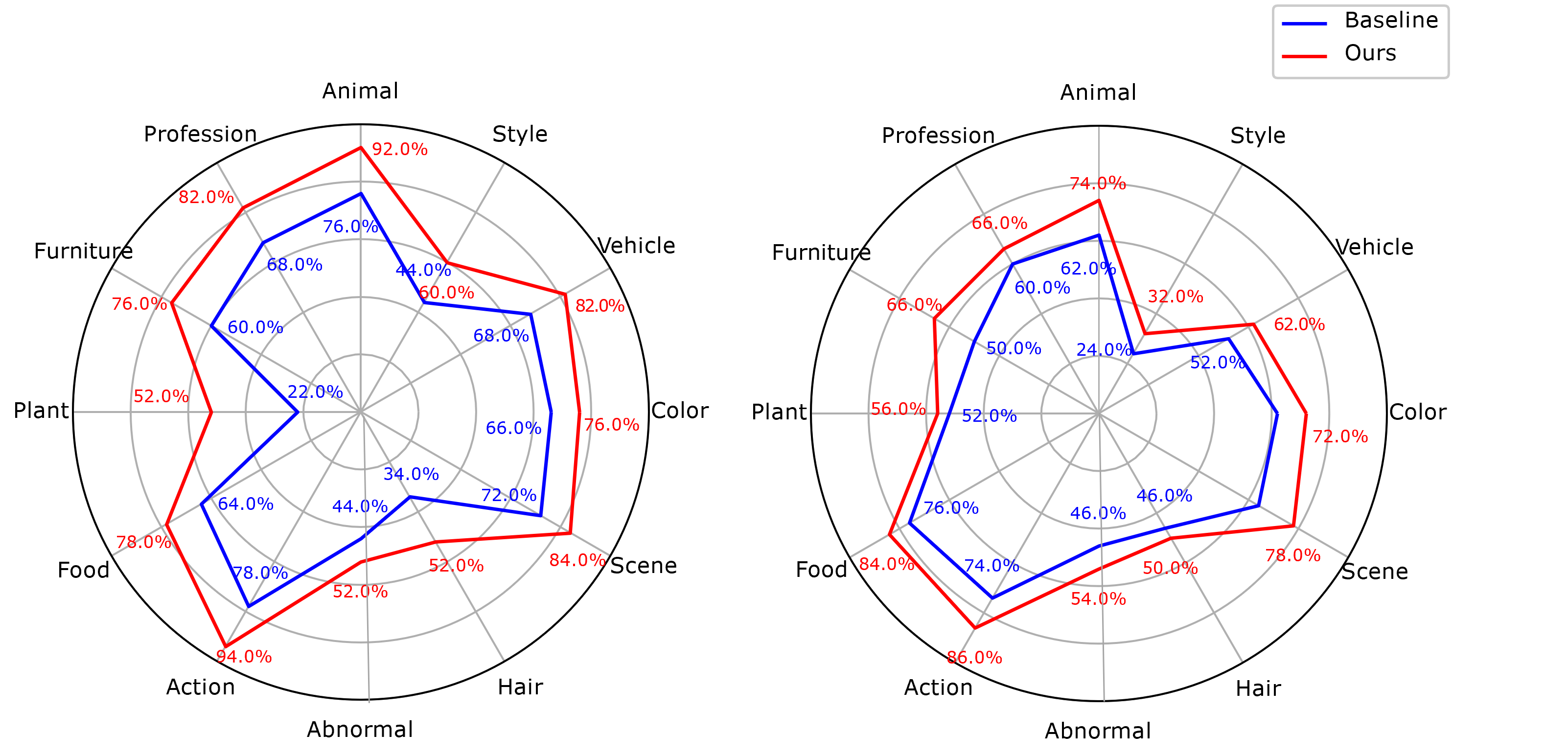
Left: AI-generated benchmarks. Right: Real-image benchmarks.Percentages indicate correct answers per ability.
Demonstrations of our method’s effectiveness across diverse real world image scenarios.

Content in red represents inaccurate information. Our model can better adhere to question instructions, rendering more precise answers.

@article{li2023stablellava,
title={StableLLaVA: Enhanced Visual Instruction Tuning with Synthesized Image-Dialogue Data},
author={Li, Yanda and Zhang, Chi and Yu, Gang and Wang, Zhibin and Fu, Bin and Lin, Guosheng and Shen, Chunhua and Chen, Ling and Wei, Yunchao},
journal={arXiv preprint arXiv:2308.10253},
year={2023}
}