About Me
I am a tenure-track Assistant Professor and PI at Westlake University, where I lead the AGI Lab. Before joining Westlake University, I worked as a scientist at Tencent.
I obtained my Ph.D. degree at the School of Computer Science and Engineering, Nanyang Technological University (NTU), Singapore, where I worked under the supervision of Prof. Guosheng Lin. I also work closely with Prof. Chunhua Shen and Prof. Rui Yao in research. I was recognized among World's Top 2% Scientists by Stanford University in 2023 and 2024.
To learn more about our lab, feel free to contact me or any member of our team😊
Research Interests
My current research focuses on Generative AI, including theoretical foundations of generative models, multimodal generative modeling, and multimodal intelligent agents. In the past, my work has also spanned broader areas in machine learning and computer vision.
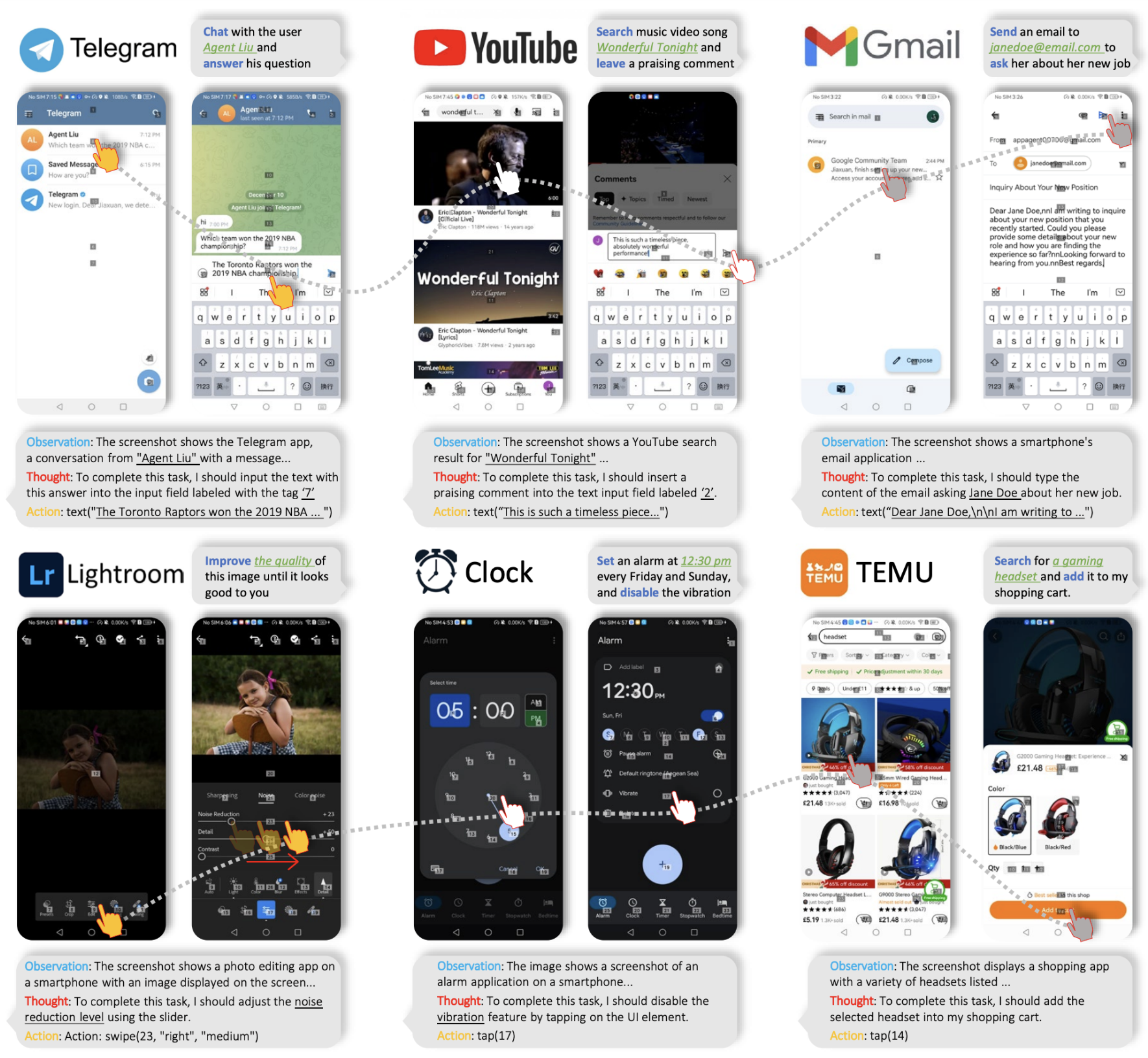
Recently, my group has developed several influential research projects, including AppAgent, the first mobile GUI agent framework and the second most-cited CHI paper over the past four years; GaussianEditor, the first work on Gaussian editing; and the MeshAnything series, the first autoregressive approach for general 3D mesh extraction.
News
Scroll for moreAcademic Service
- Associate Editor for TCSVT since 2024
- Area Chair for ICML 2026, ICLR 2026, CVPR 2026, ACL ARR 2025, ACM Multimedia 2025, IJCNN 2025
- Reviewer for T-PAMI, ICLR, CVPR, NeurIPS, etc.
Hobbies
I like singing and playing football. I am a loyal fan of FC Barcelona PSG Inter Miami .
My favorite singers are Jacky Cheung and Freddie Mercury.
Selected Projects

MeshAnything: Artist-Created Mesh Generation with Autoregressive Transformers
ICLR 2025
MeshAnything V2: Artist-Created Mesh Generation with Adjacent Mesh Tokenization
ICCV 2025
GaussianEditor: Swift and Controllable 3D Editing with Gaussian Splatting
CVPR 2024


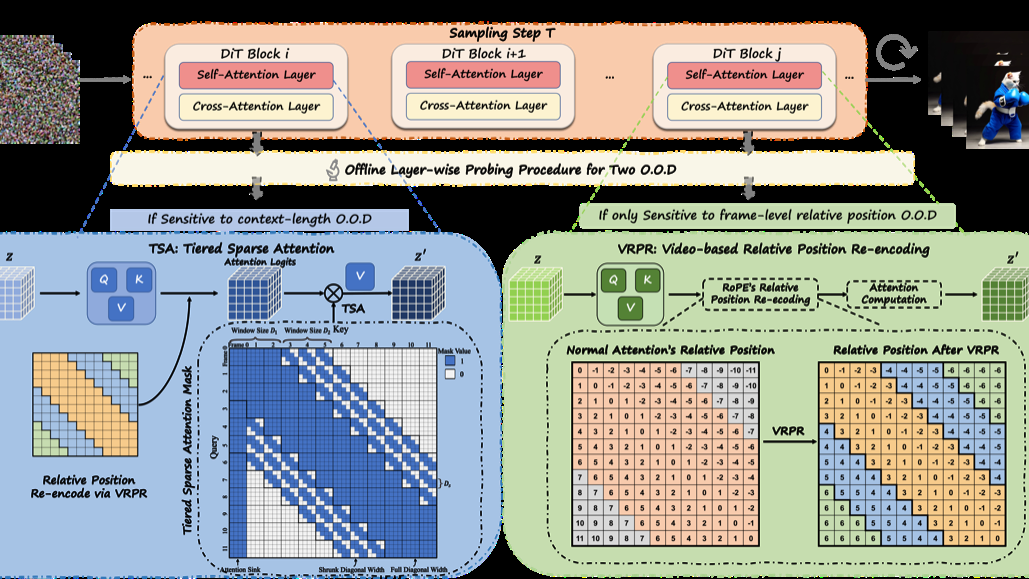
Detail++: Training-Free Detail Enhancer for Text-to-Image Diffusion Models
IEEE TIP 2026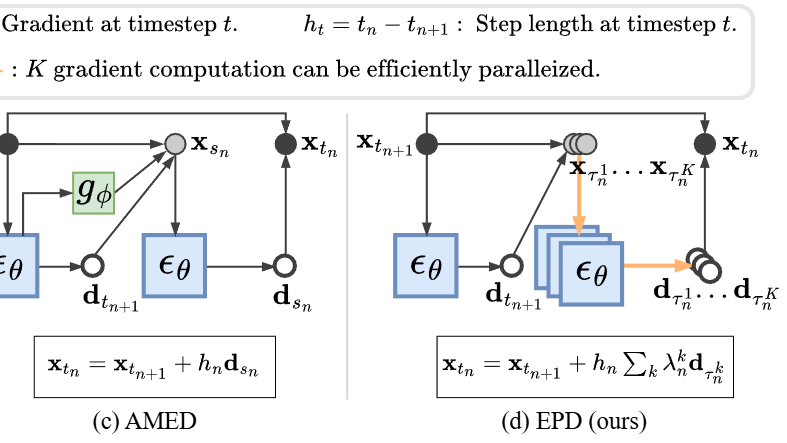
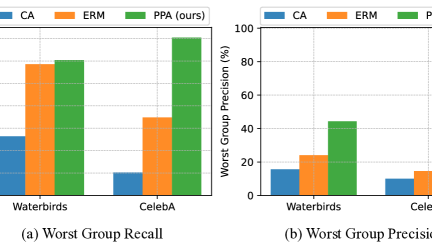
Parallel Diffusion Solver via Residual Dirichlet Policy Optimization
IEEE TPAMI 2026
SwitchCraft: Training-Free Multi-Event Video Generation with Attention Controls
CVPR 2026
CRAFT-LoRA: Content-Style Personalization via Rank-Constrained Adaptation and Training-Free Fusion
CVPR 2026
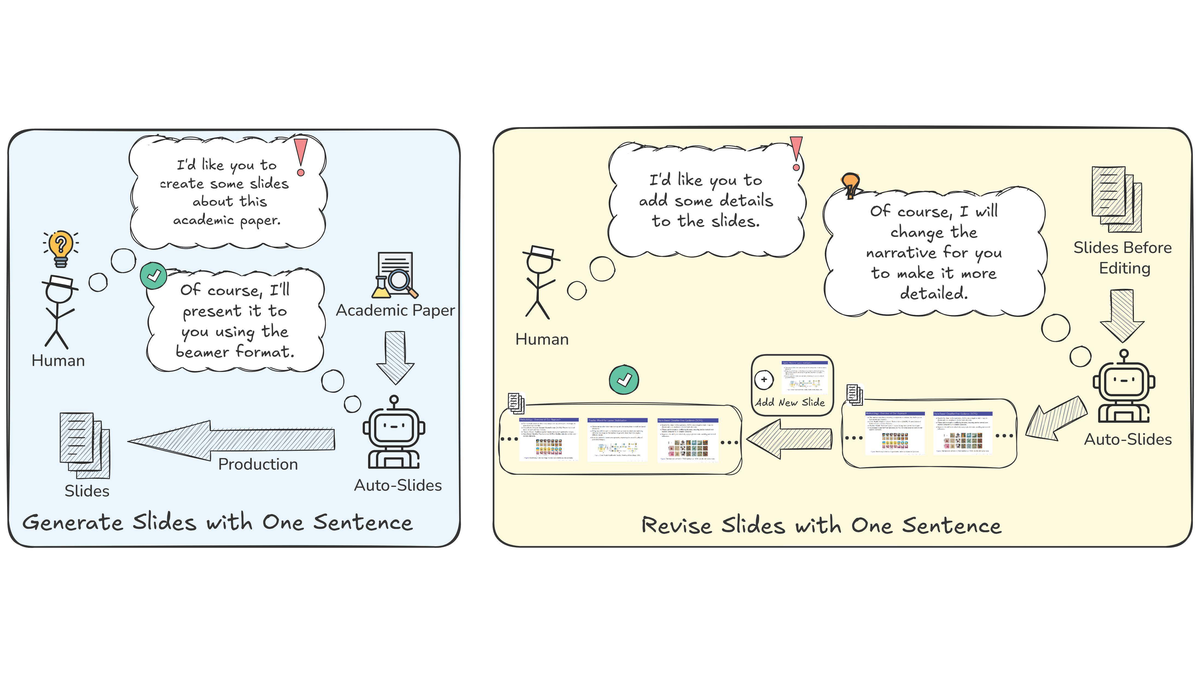
Auto-Slides: An Interactive Multi-Agent System for Creating and Customizing Research Presentations
ICME 2026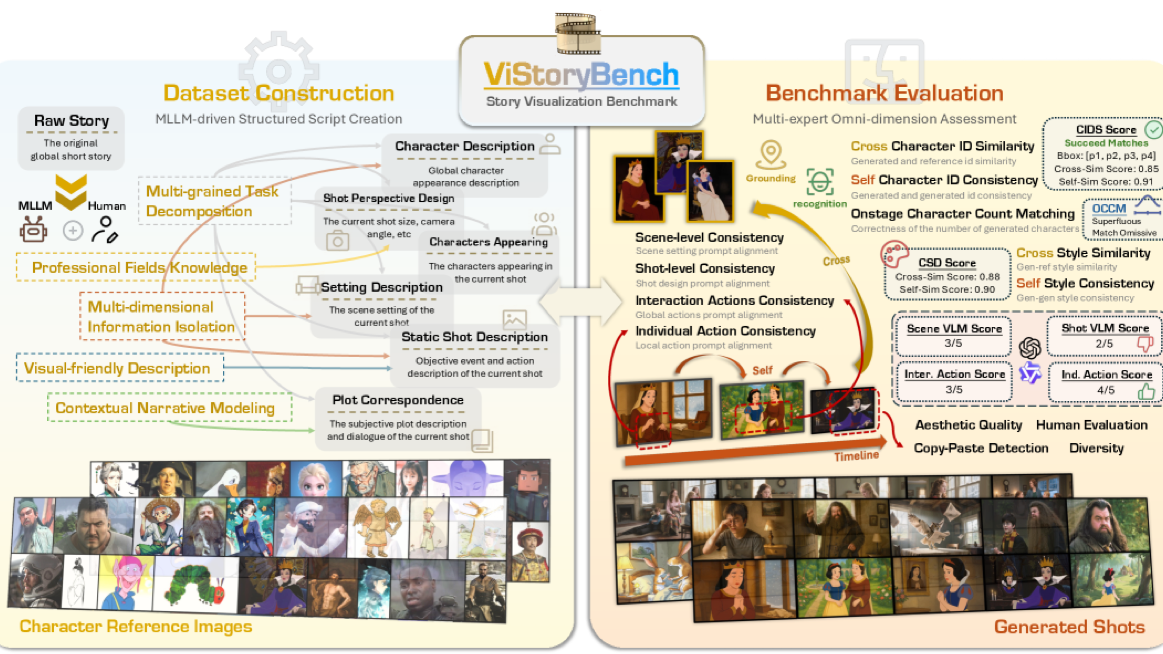

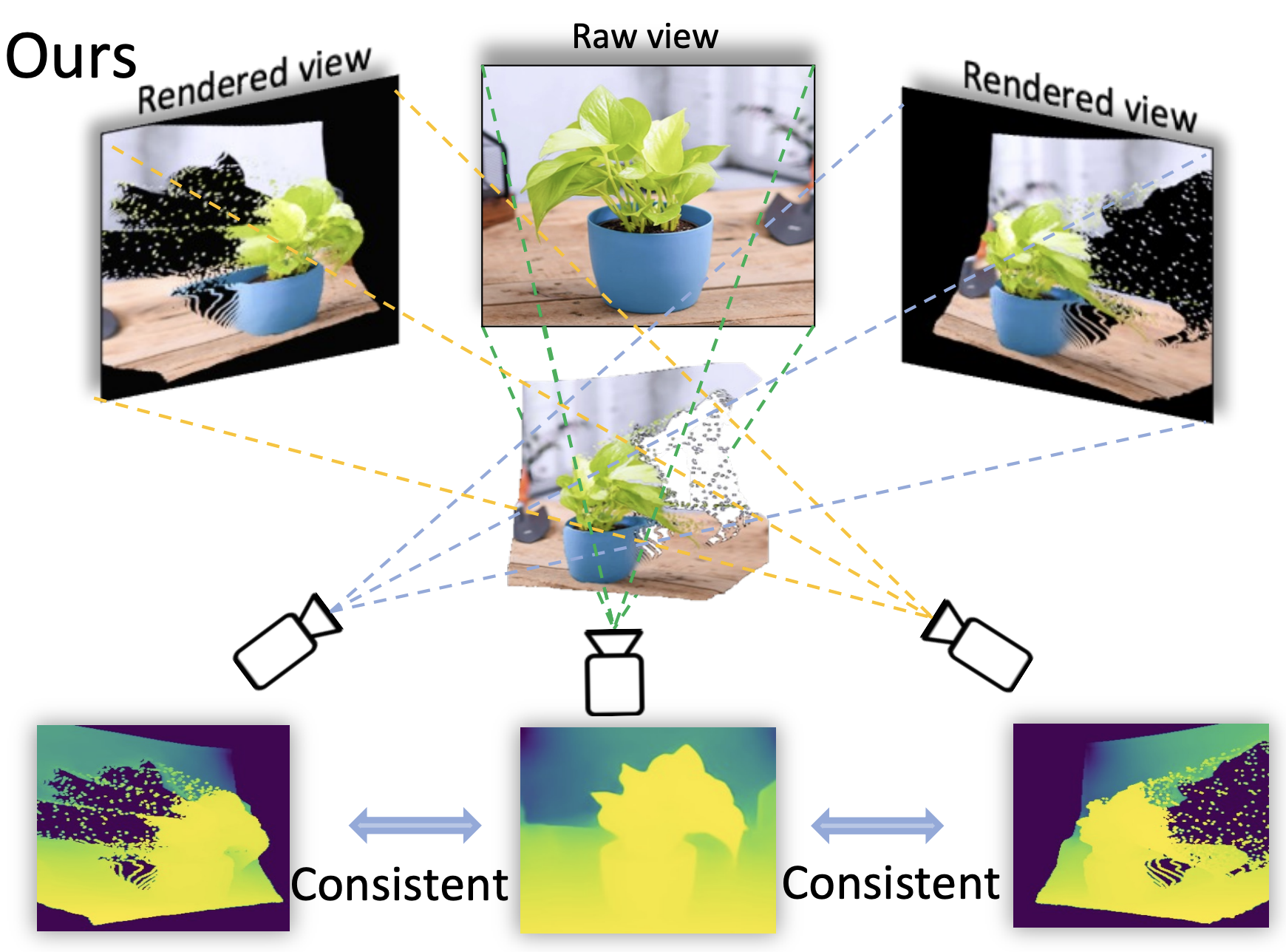
Distill Any Depth: Distillation Creates a Stronger Monocular Depth Estimator
CVPR 2026 Findings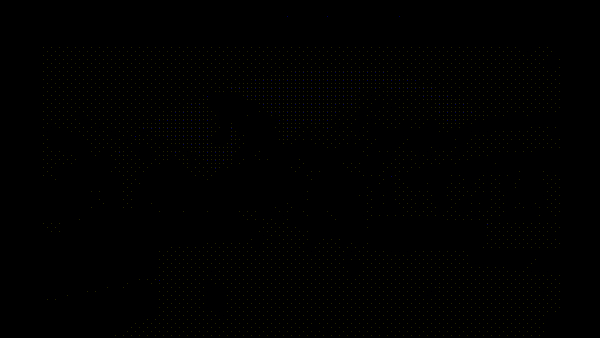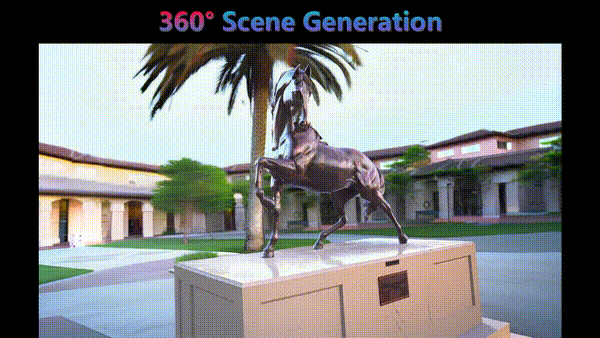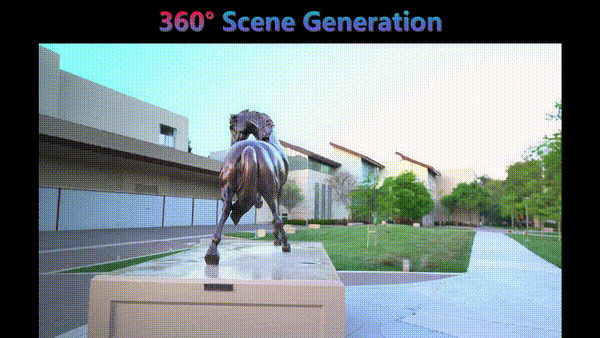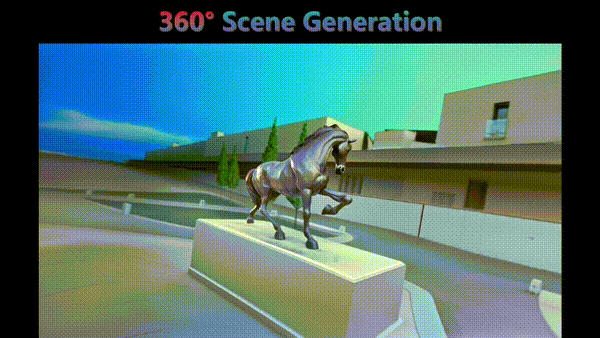
Taming Video Models for 3D and 4D Generation via Zero-Shot Camera Control
CVPR 2026
FlowDirector: Training-Free Flow Steering for Precise Text-to-Video Editing
CVPR 2026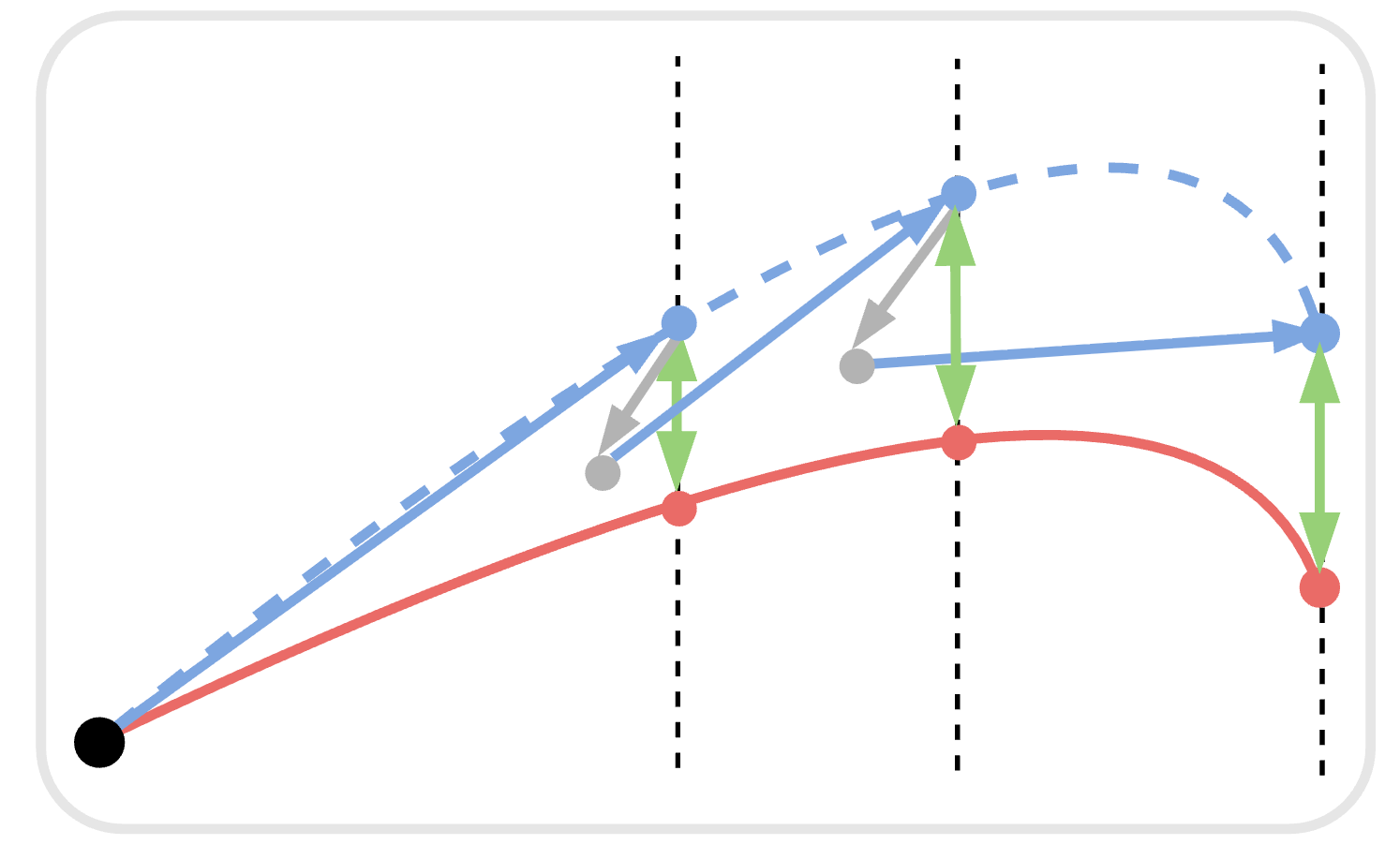
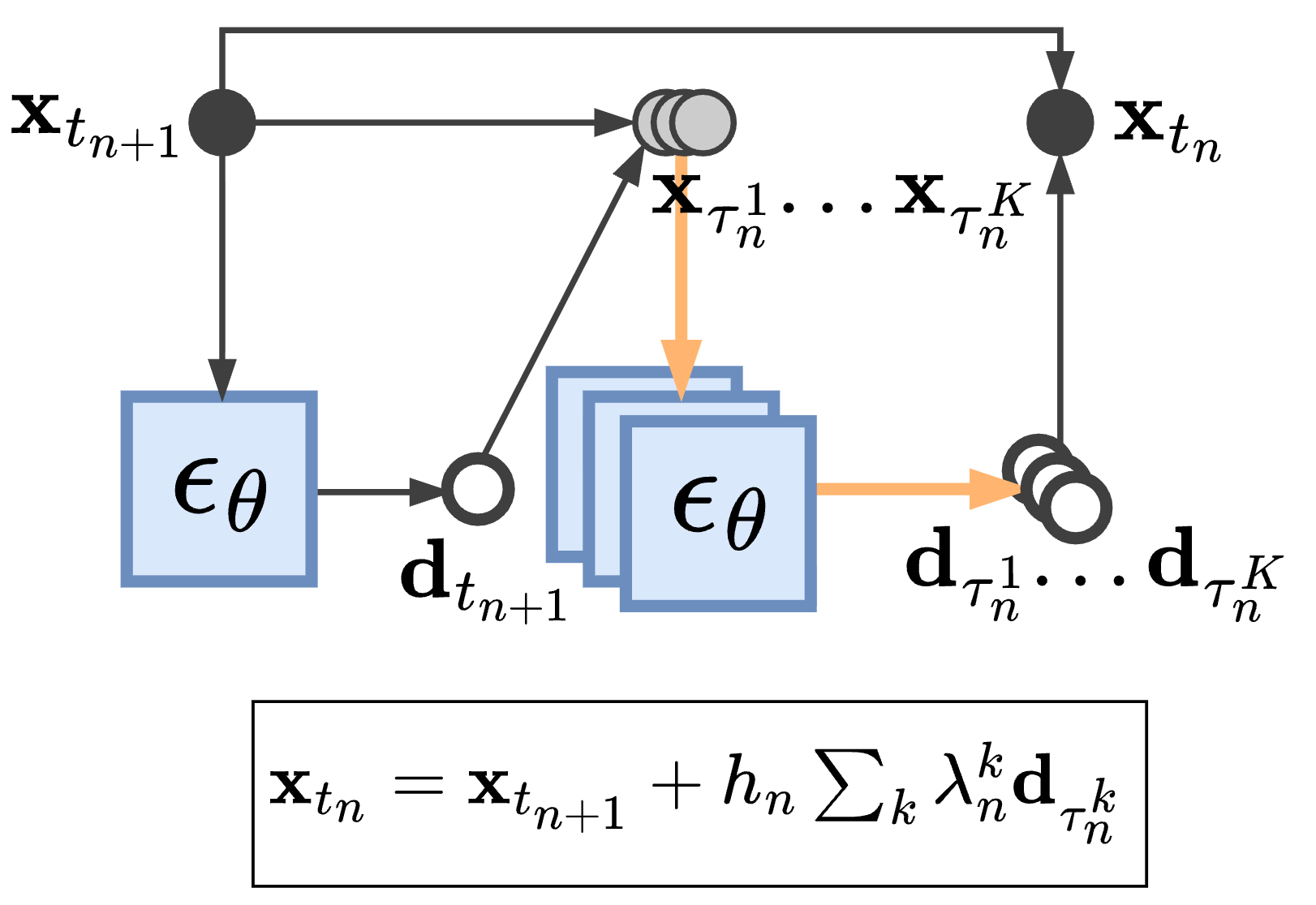



ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model
IEEE Transactions on Multimedia 2025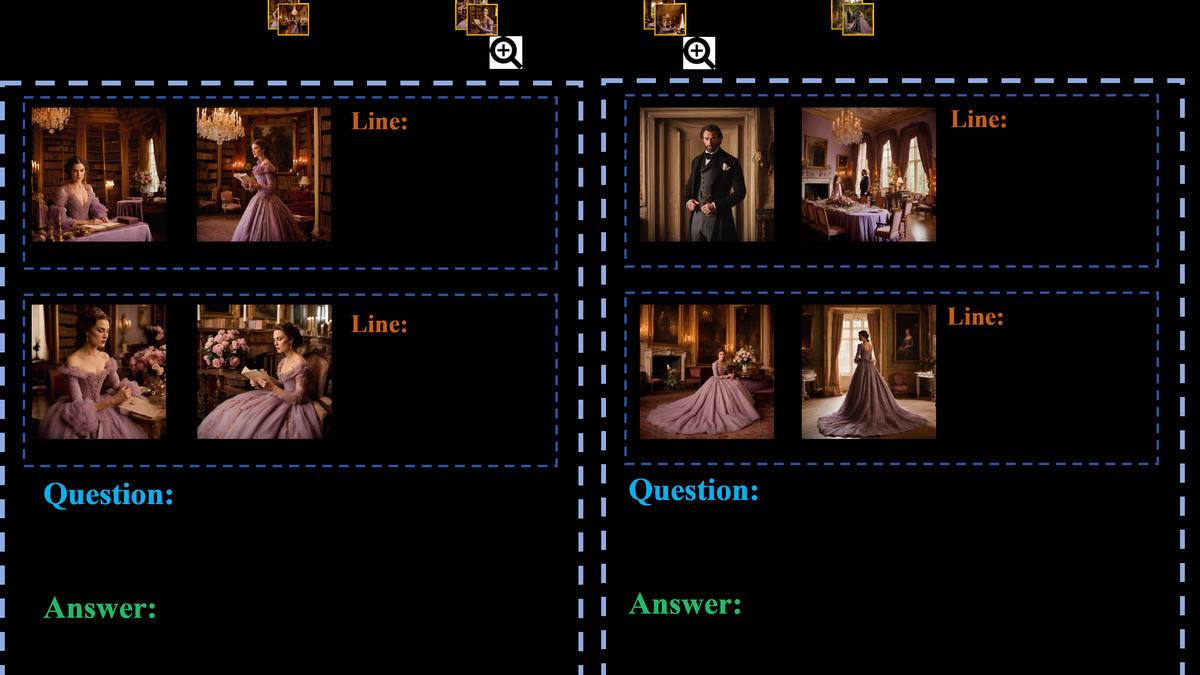
DreamFrame: Enhancing Video Understanding via Automatically Generated QA and Style-Consistent Keyframes
ACM MM 2025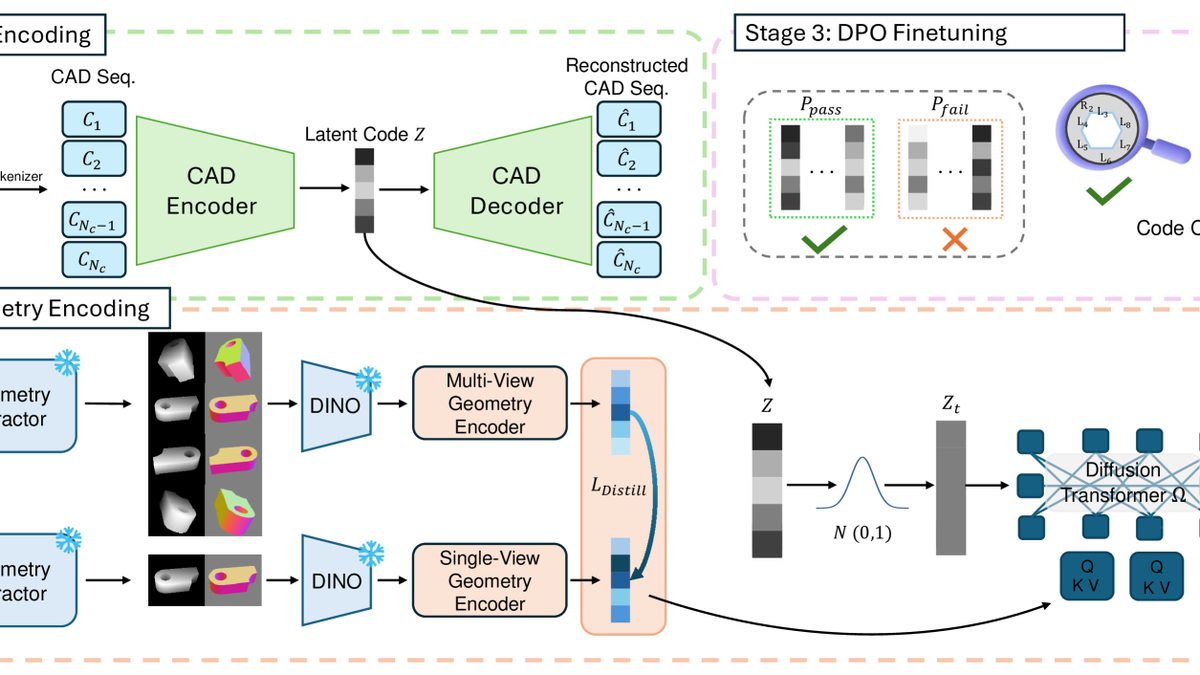
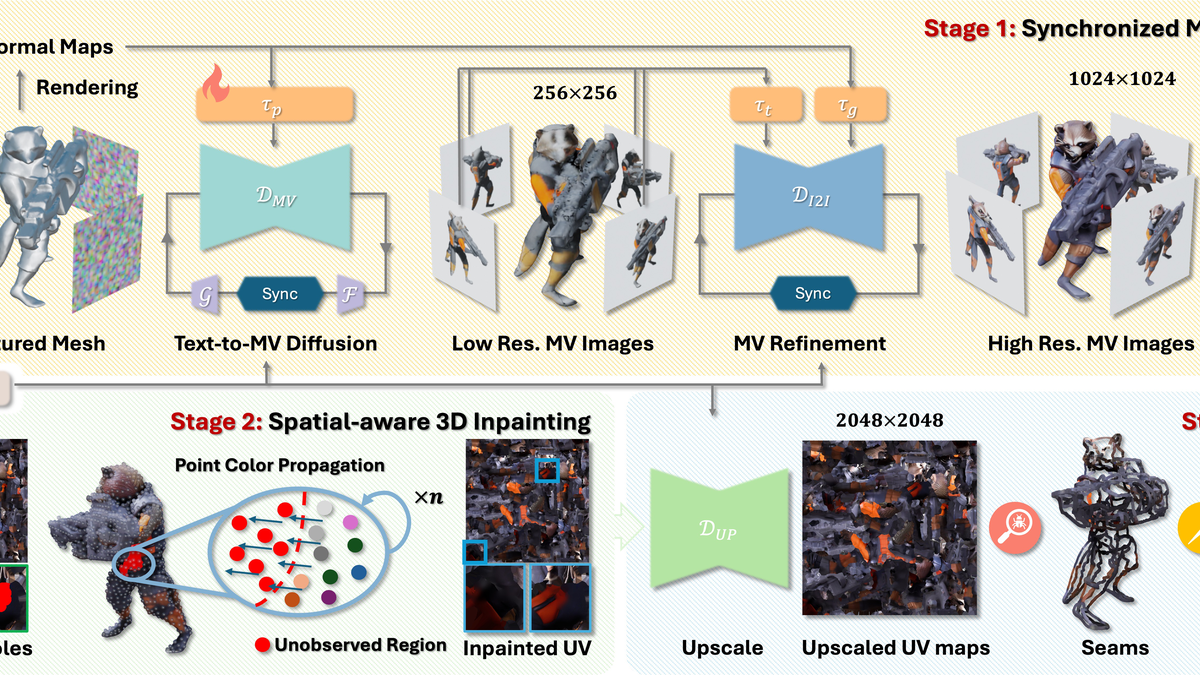

StyleStudio: Text-Driven Style Transfer with Selective Control of Style Elements
CVPR 2025


StableLLaVA: Enhanced Visual Instruction Tuning with Synthesized Image-Dialogue Data
ACL 2024
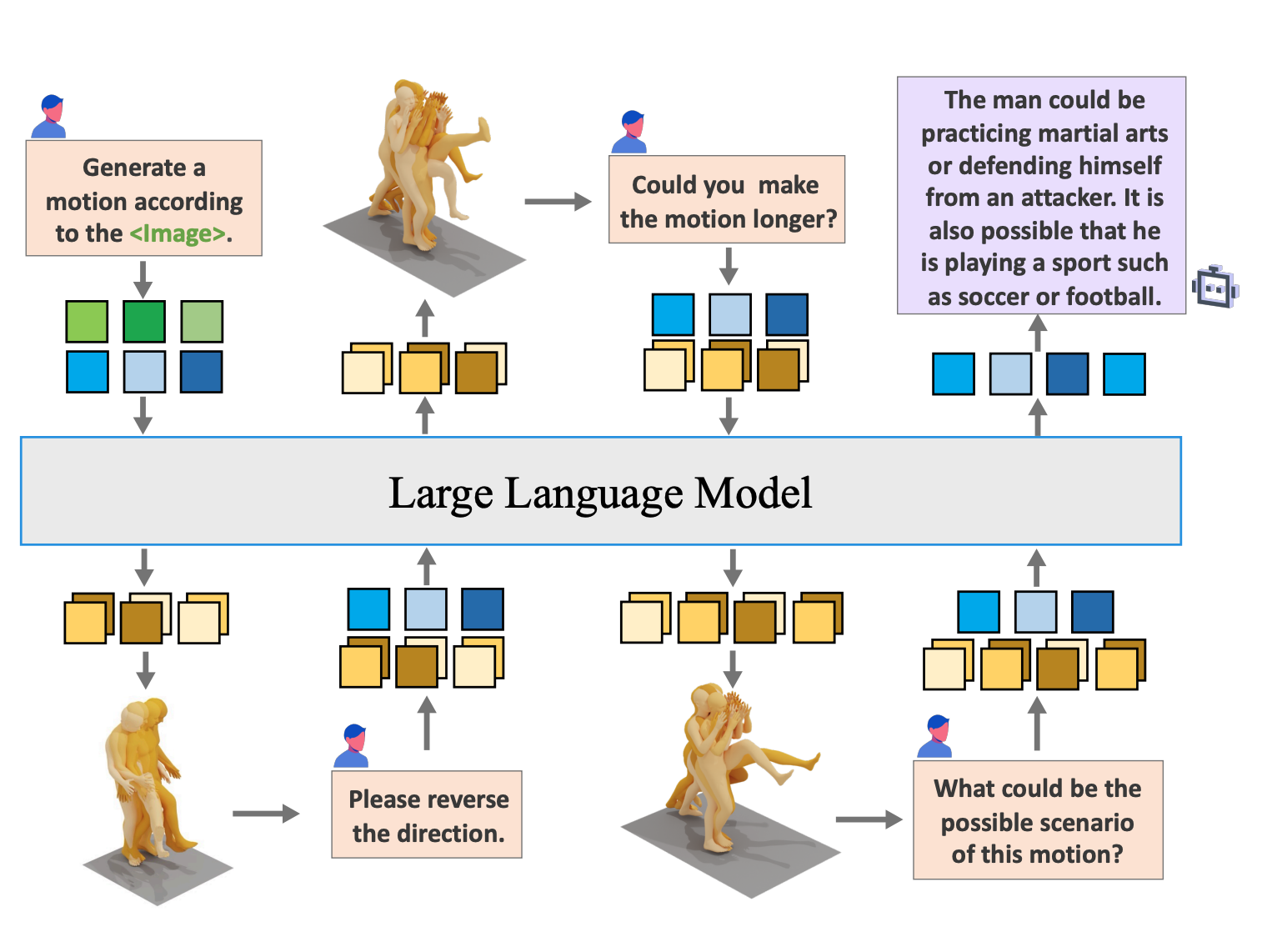
MotionChain: Conversational Motion Controllers via Multimodal Prompts
ECCV 2024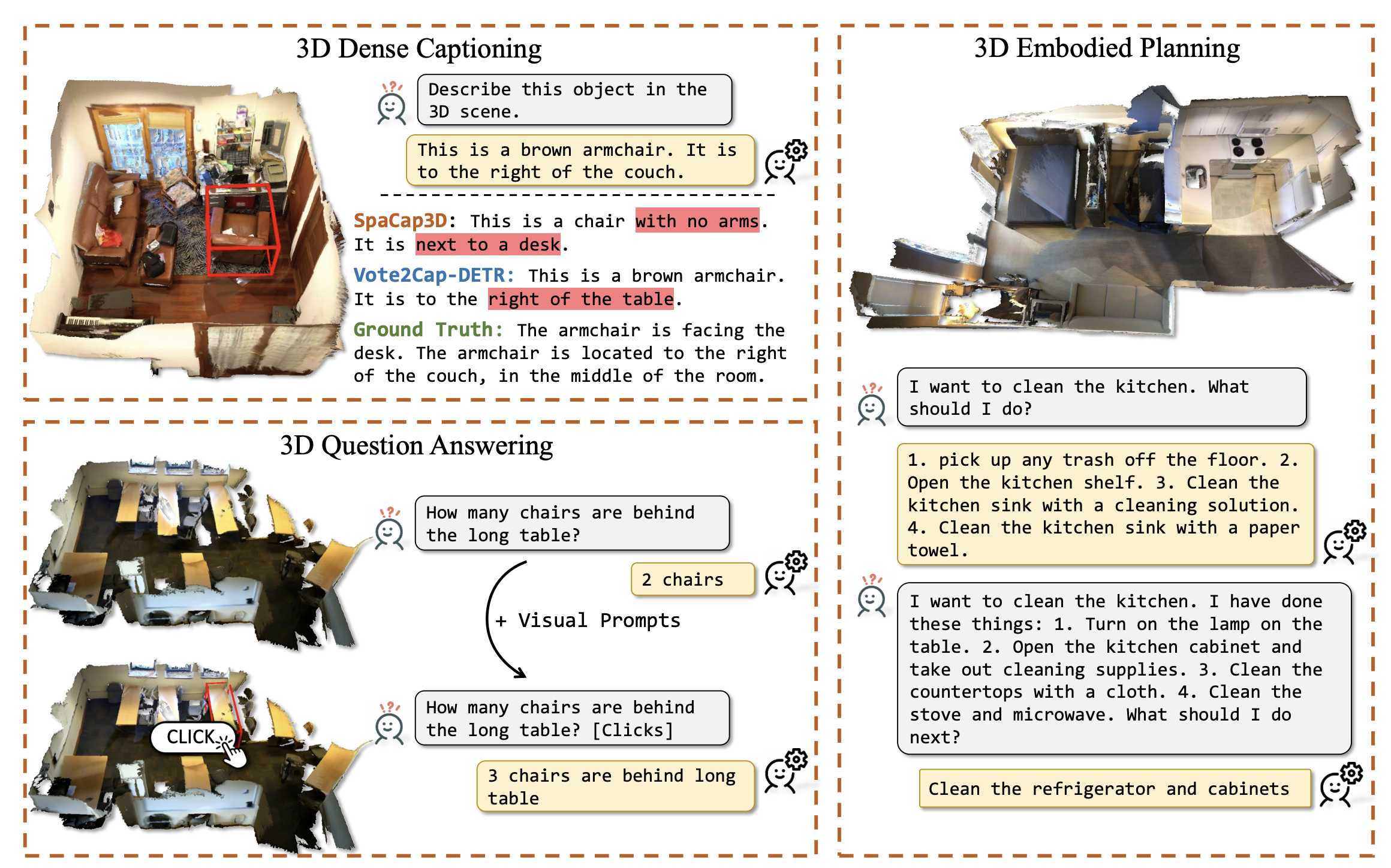
LL3DA: Visual Interactive Instruction Tuning for Omni-3D Understanding, Reasoning, and Planning.
CVPR 2024

EMMA: Your Text-to-Image Diffusion Model Can Secretly Accept Multi-Modal Prompts
Arxiv 2024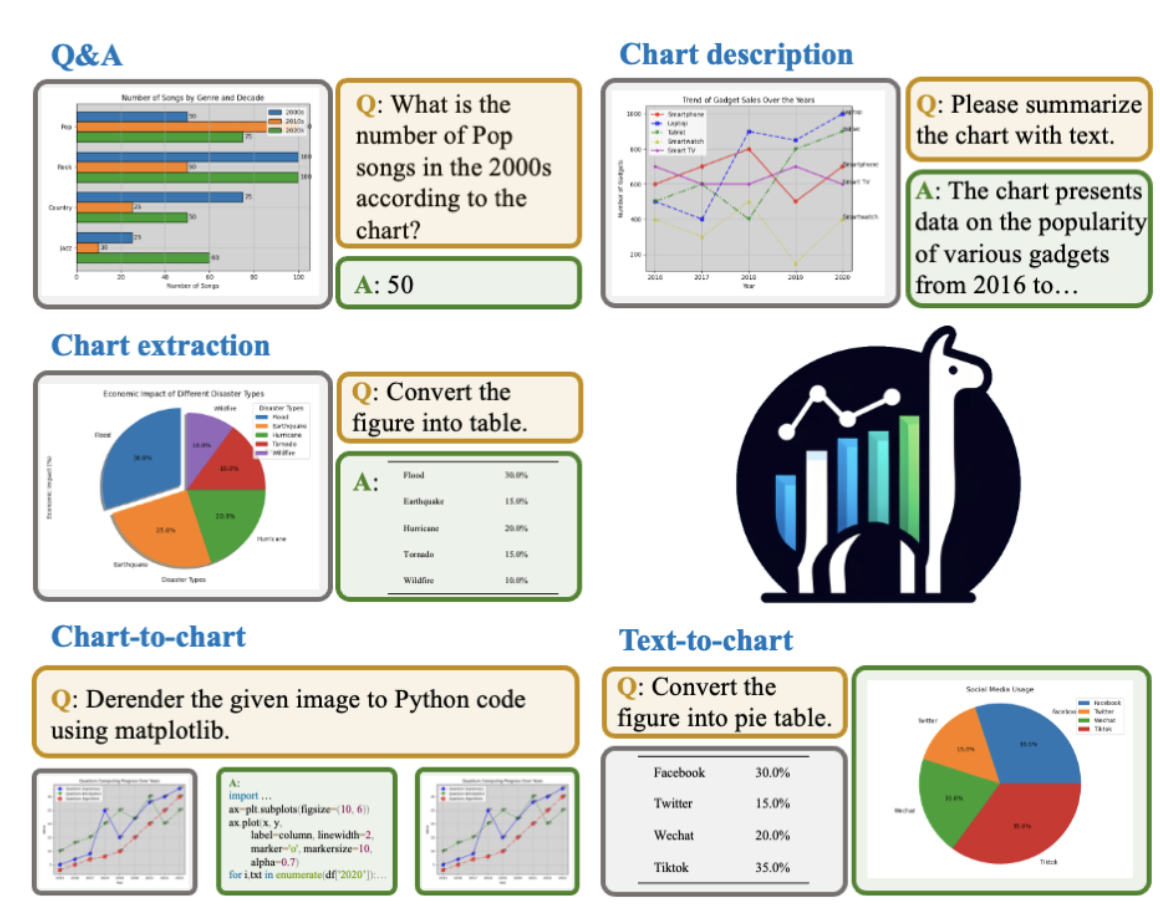
ChartLlama: A Multimodal LLM for Chart Understanding and Generation
Arxiv 2023
Lab Gallery






